I lived a few stories up in my old Jones St apartment. I couldn’t buzz people in, and there was no functioning elevator. I loved to use apps like Instacart, Rinse, and Uber Eats to get deliveries, but I didn’t love making the trip down and up to receive those deliveries. This served as the creative inspiration for an automated crane system. I was pleasantly surprised at the response to the system, some delivery people expressed obvious joy at being asked to put the delivery in the bag that was lowered, and none ever expressed anger or disappointment.
Here you can see the crane arm in action, first going out and then going back inOne button at my desk opened and closed the window, another sent the crane arm out and backHere you can see the crane in action, hosting up delivery of fresh laundry from RinseHere you can see an early version of the winch being tested with the rotary encoder
Seems obvious in retrospect, but originally I didn’t think I’d need a crane arm to give adequate clearance from a small ledge beneath my window.
An L298n H Bridge proved very inadequate as a motor controller. On occasion, it would get too hot because too much wattage was flowing through it, and would need a few minutes to cool down before resuming operation.
The vibration produced by the cranes would routinely cause screws to come loose until I began to take additional measures to counter-act this.
Components:
2x Arduino Uno Rev 3 (one for the crane arm, one for the crane itself)
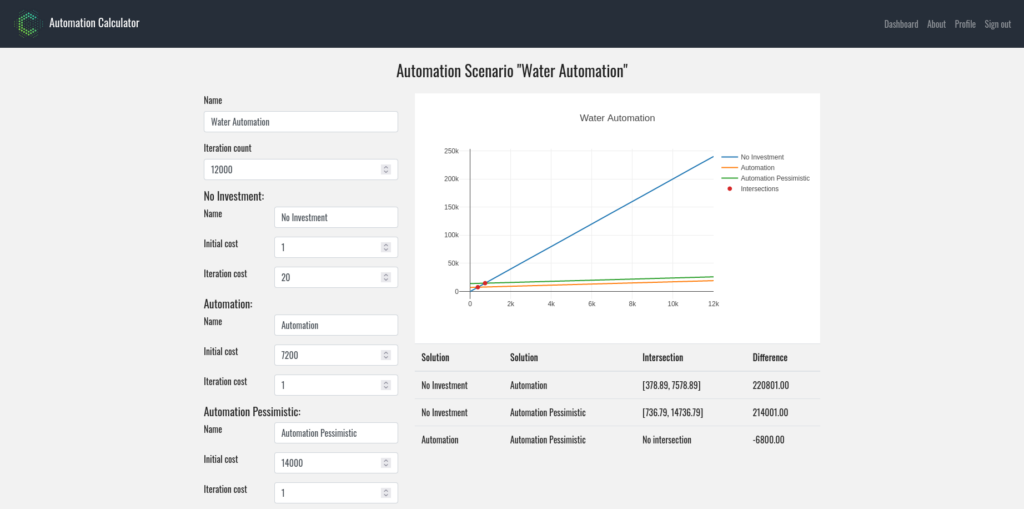
As someone who likes to automate things with software and hardware, I decided to create an open source web app with Ruby on Rails that will help me determine what ideas I have will save me the most time.
It works by providing a form for a user to enter in details about how long a process takes them, how long it will take them to automate it, etc.
Users can get a quick graph by visiting the home page.
They can also save many scenarios and compare them if they create an account. A classic email/password option is available, as well as creating an account with Google or Github via OAuth2.
I built this to automatically refill my glass of water at my desk. It uses an HX 711 load cell connected to an Arduino to open/close a solenoid valve based on the weight of the glass of water. With no weight, it closes the valve. When the weight is between a minimum threshold and a maximum threshold, it opens the valve to let more water into the glass.
Here you can see the controlling arduino, as well as the solenoid valve, L298N for that valve, and power supply regulator for the arduino.
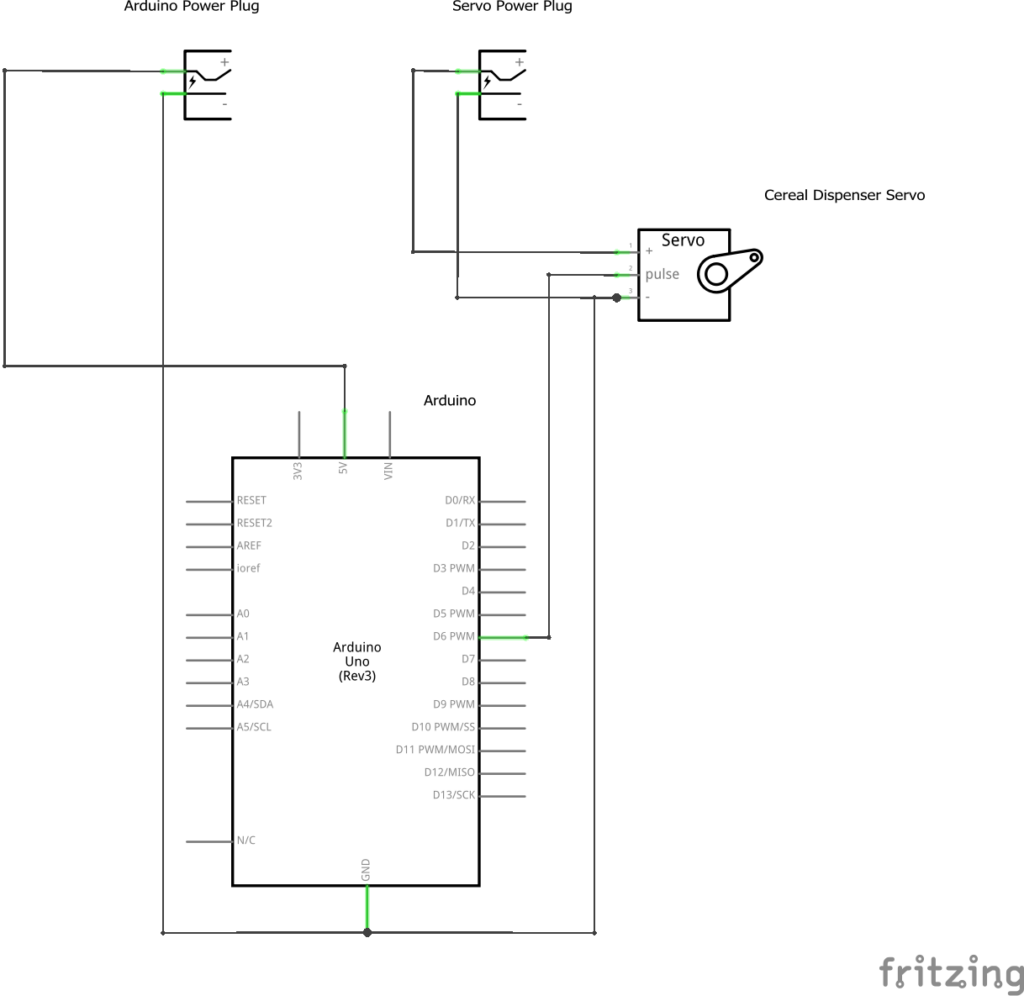
This is an automated cereal dispenser I made with an Arduino to dispense cereal into a bowl automatically every day at 7 am. One less thing to do for the day. Note this shows only one loop of many, the Arduino can be configured to repeat this loop to fill up the bowl as much as I like.
Automatically dispensed cereal at 7 am sharp every morning, could be enabled/disabled by a smart plug on my iPhone
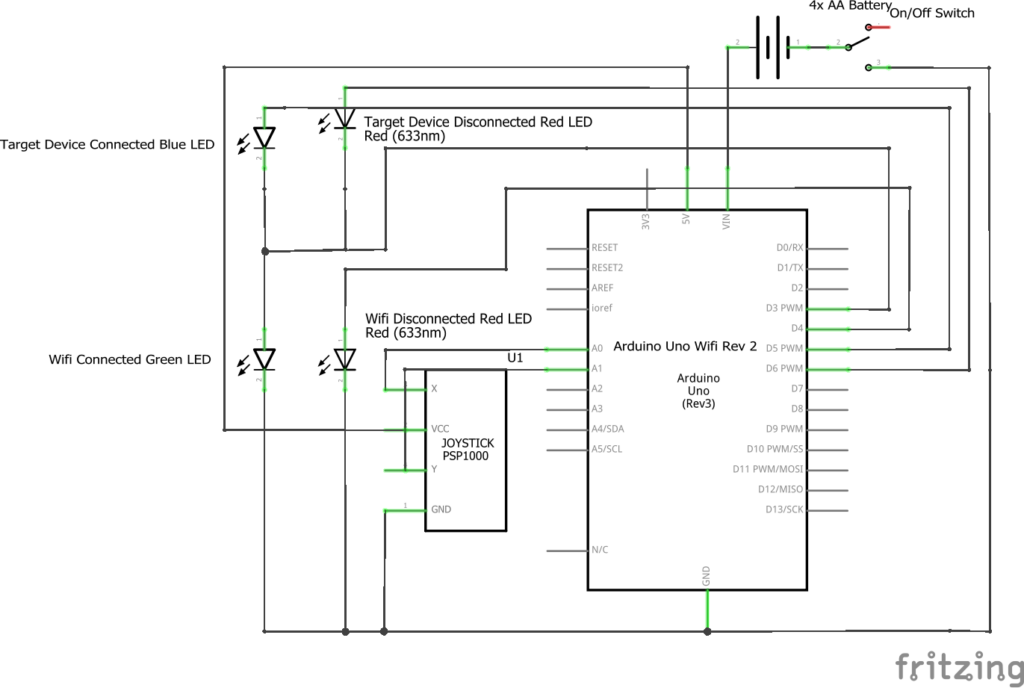
I wanted the option to control my Wifi remote-controlled car with a traditional joystick setup, so I made this.
Here you can see the controller in action, connected to the car via WiFi, to drive the car.Here is a close-up of the finished controller, you can see it is connected to the WiFi network but not the car via the LEDs on the left.
This remote was built to drive this remote control car. The JSON structure of its commands was intentionally built to be generic, however, so it could be re-used to drive other remote-controlled vehicles without needing to modify/reprogram it.